

– Nati Shalom, CTO GigaSpaces, says:
Real-time big data is an increasingly relevant topic, as more and more users are gaining experience with big data storage systems. Real-time big data aims to process data streams as they enter the system, rather than waiting for batch analysis or queries, in accordance with the currently employed “store everything” approach. This practice tends to delay analysis for batch processing at a later phase, where data can be scrubbed, correlated, and reported on. But “store everything” creates a challenge for any system that needs to process data as it arrives, which has led to, by necessity, the creation of in-memory processing systems. Only in-memory processing can hope to deal with the potentially enormous throughput of real-time stream processing. And the need for real-time processing is clear: A recent survey conducted by Ventana Research indicates that processing speed is second only to larger storage capacity as a big data priority, and a recent Gartner release identified in-memory technology applied to real-time big data as a top technology trend.
Twitter Storm is a popular open source framework and runtime for processing streams of data in real time. In order to store state (streams and analytics), Storm relies on external systems, typically a big data store (such as Cassandra) and some kind of messaging system (such as Apache Kafka). This paper presents an architecture that uses the GigaSpaces XAP in-memory computing platform as both a source of data and state for Storm, and for long-term persistence by fronting asynchronous persistence to Cassandra. The use of in-memory technology for queuing, state, and persistence, removes disk-based (or SSD-based) persistence from the real-time data flow, maximizing performance without sacrificing reliability.
Defining Real-Time Big Data
For the purposes of this paper, real-time big data means processing analytics from very large volumes of messages as they arrive from various sources, and then directing them to archival big data stores. Real-time analytics are responsive to events as they arrive; queries made to data stores after persistence has occurred do not qualify. A highly scalable real-time big data processing system is ultimately dependent on the ability of connected big data stores to sustain very high write throughput. Cassandra, being explicitly designed to process writes efficiently, is an ideal big data store for real-time analytics.
Storm is a framework and runtime that allows sequences of messages (tuples) to be processed in an efficient and intuitive way. Storm processes data entirely in memory, in a compute cluster. It supplies abstractions for message sources (spouts), processing nodes (bolts), and message flows (topologies). A topology is the unit of deployment to a Storm cluster, and it processes tuples until it is killed. Storm interacts with message sources in several ways, including unreliable, at-least-once, and exactly-once paradigms. Messages can be processed in batches for efficiency. The runtime allocates processing to the cluster based on hints supplied by the topology author.
Challenges
Performance: Storm runs in-memory, and can process large volumes of data at in-memory speed. However, a typical storm architecture needs to interface with a data source for its input and another data source for its output. In addition, aggregations (analytics) are often done in-memory for observation and/or querying. In this context, overall performance is determined not by Storm itself but by the data input and output sources. These interfaces are, therefore, the limiting factor: they often rely on file-based message queues for streaming, and NoSQL for data storage, and are at least an order of magnitude slower than Storm itself.
Complexity: Storm itself consists of several moving parts, such as a coordinator (ZooKeeper), state manager (Nimbus), and processing nodes (Supervisor). The NoSQL data store also comes with its own cluster management. In addition, a typical big data system comes with even more components, such as the application front end, a reporting database, and so on. This makes the process of managing the deployment, configuration, fail-over, and scaling of such a system quite complex.

Addressing the Performance Challenge
Because Storm is an in-memory technology, it generally outstrips the performance of any non-memory-based technology it interfaces with. These interfaces become bottlenecks for the overall system performance. Storm’s interfaces are the sources of data (Spouts), the sinks of data (potentially a big data store), and processing state (typically a big data store). If you replace these traditionally disk-based persistence mechanisms with advanced data grid technology, the roadblocks are removed, and the system can function with extreme efficiency.
To supply in-order, process-once semantics, Storm requires sources of data to provide replayable data streams. In order to maximize efficiency, Storm requires the same data sources (Spouts) to provide data (tuples) in replayable batches. By using GigaSpaces XAP as the stream queuing mechanism, data can be supplied in a batched, reliable, replayable manner as required by the most advanced Storm configurations.
Storm provides a mechanism for storing and updating state (e.g., counters and aggregations). XAP can be used here as an alternative to disk-based, or volatile in-memory storage (like memcached). State information about the streaming data is available in XAP for querying, and/or for persisting to a data store.
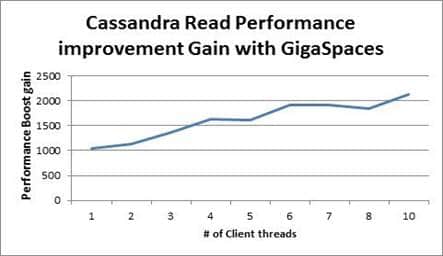
When using Storm to produce output for a big data store, it can instead write to XAP directly. XAP can then asynchronously update the store, freeing Storm to continue processing rather than waiting for I/O. Also, XAP can provide cached access to the underlying data store, greatly speeding read performance.
Addressing the Complexity Challenge
To meet the complexity challenge, the following illustrates a DevOps automation approach using Cloudify in conjunction with Chef or Puppet.
Each service – Storm, Cassandra, and our in-memory data store – is wrapped with a deployment recipe that abstracts the underlying details on how to manage it. Cloudify uses these recipes to automate the deployment of the entire stack. In this way, you only need to interact with Cloudify for the deployment, configuration, scaling and fail-over of your stack, rather than being required to separately manage each individual component. In addition, Cloudify abstracts the underlying infrastructure, enables you to use the same deployment recipe across different environments – testing, production, etc. You can also use the same approach to deploy your apps based on the type of workload. You can use a public cloud for running sporadic workload, leveraging the elasticity of the cloud and also enabling you to create and scale the environment as well as rip it off completely when done. At the same time, you can choose bare-metal machines for I/O-intensive workloads, and so on.

Conclusion
Real-time big data is about handling very large workloads in real time. The volumes of data are far greater than can be persisted by a conventional database, and the data is often unstructured. In-memory technology is the best-suited solution to handle this. Storm is a technology that provides very high-speed real-time processing, but which delegates stateful operations to external systems. GigaSpaces XAP provides highly available in-memory persistence and queuing for Storm, as well as asynchronous persistence to an underlying big data store. The deployment and management of multiple clusters (Storm, XAP, NoSQL) can be daunting and ad-hoc. Here Cloudify can provide a DevOps/recipe-oriented management and deployment infrastructure that provides unified management, self-healing, and dynamic scalability on both virtual and physical hardware.
Other Resources:

{kind=link}